In my Tesseract MICR OCR project was used custom trained language like "micr", where language data compiled into "tesstrain/micr.trained" file. Tesseract executed with "-l micr" option, telling program to use this micr font custom trained data. This article provides some notes and ideas how to create this kind of files. It can be used to improve/tune existing OCR process or make web scrapping better to train with custom captcha symbols, etc.
Tesseract 4 introduced new LSTM model and tools to generate "trained" files. E.g. the latest Tesseract 5 provides MAKE file based LSTM model tesstrain training tool. This process a bit complicated and need more resources and time to create data. But looks like old Tesseract 3 approach still work in version 5. So I've created some instructions how to make something simple in case when you have single image, simple grammar and few symbols to recognize. I tested this on MacOS 12.5, but it should work well on Linux as well. Looks like old Tesseract 3 training process still works.
As sample, we will learn tesseract to read few Egyptian hieroglyphs like ABCDEF.

A) Install the latest tesseract. In my case it was 5.3.0-17-g3bed installed with homebrew:
brew update brew upgrade brew install tesseract --HEAD tesseract --version
Output:
tesseract 5.3.0-8-gda373 leptonica-1.82.0 libgif 5.2.1 : libjpeg 8d (libjpeg-turbo 2.1.3) : libpng 1.6.39 : libtiff 4.4.0 : zlib 1.2.11 : libwebp 1.2.4 : libopenjp2 2.5.0 Found AVX2 Found AVX Found FMA Found SSE4.1 Found libcurl/7.79.1 SecureTransport (LibreSSL/3.3.6) zlib/1.2.11 nghttp2/1.45.1
B) Install training tools according to "Building training tools" docs ( TrainingTesseract-5.md, TrainingTesseract-4.00.md ). I've used this setup on MacOS:
brew install cairo pango icu4c autoconf libffi libarchive export PKG_CONFIG_PATH=\ $(brew --prefix)/lib/pkgconfig:\ $(brew --prefix)/opt/libarchive/lib/pkgconfig:\ $(brew --prefix)/opt/icu4c/lib/pkgconfig:\ $(brew --prefix)/opt/libffi/lib/pkgconfig ./configure
C) Download and extract somewhere jTessBoxEditor tool (it requires in Java runtime to be installed as well). I've used version 2.4.1 to download. Once jTessBoxEditor ZIP file downloaded and extracted, in terminal navigate to this folder and run:
java -Xms128m -Xmx1024m -jar jTessBoxEditor.jar
Tesseract 3 basic docs suggest to use this format for base naming: [lang].[fontname].exp[num] . In this exercise we will use "foo" value for [lang], "bar" value for [fontname] and "0" for [num] : foo.bar.exp0
1) Create box files. Tesseract by default provide tools to create foo.bar.exp0.box file from image:
tesseract foo.bar.exp0.tif foo.bar.exp0 batch.nochop makebox
As result default foo.bar.exp0.box file is created. But it should be usually manually modified, because tesseract doesn't know anything about used font, or it can have some symbols and not font at all to be trained. For this purposes use jTessBoxEditor tool and precisely fix all:
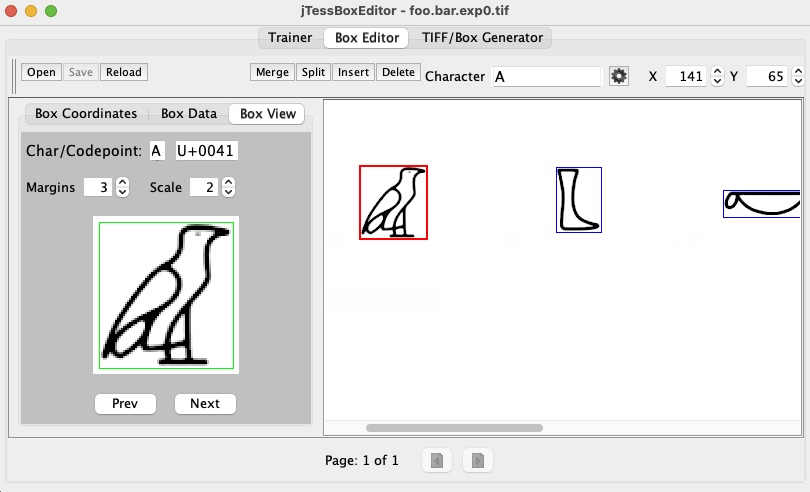
2) Run tesseract for training for each image and create ".tr" file, "foo.bar.exp0.tr" in our case:
tesseract foo.bar.exp0.tif foo.bar.exp0 --psm 6 box.train
NOTE: I've used page segmentation mode 6, because default one usually produces some errors like: FAIL! APPLY_BOXES: boxfile line 2/B ((337,79),(382,144)): FAILURE! Couldn't find a matching blob
3) Compute the character set, as result "unicharset" file is created:
unicharset_extractor foo.bar.exp0.box
4) Generate "font_properties" file. According to doc this is text file, where each line has format like: <fontname> <italic> <bold> <fixed> <serif> <fraktur>
echo "bar 0 0 0 0 0" > font_properties
5) Clustering.
[mftraining]. It will create three files: "inttemp", "pffmtable", "shapetable":
mftraining -F font_properties -U unicharset -O foo.unicharset foo.bar.exp0.tr
[cntraining].This will output the "normproto" data file:
cntraining foo.bar.exp0.tr
6) Combine and put it all together.
Rename files from previous step (shapetable, normproto, inttemp, pffmtable) with a "[lang]." prefix:
mv shapetable foo.shapetable
mv inttemp foo.inttemp
mv pffmtable foo.pffmtable
mv normproto foo.normproto
[combine_tessdata]. Create "foo.traineddata" file:
combine_tessdata foo.
That is pretty all. As next step hope you know what to do with "foo.traineddata" file. E.g. it can be copied to tessdata directory, and then run tesseract with "-l foo" language and see progress.
ABCDEF characters from ancient alphabet used in example. As start point provided TIFF file "data/foo.bar.exp0.tif" with hieroglyphs.
For this image manually created and edited "data/foo.bar.exp0.box" box file.

Default tesseract for this TIFF image generates rubbish like:
tesseract foo.bar.exp0.tif stdout -l eng --psm 6 “i tlwaoae> ds
To simplify training process was created "run.sh" script. It should be executed in "tesseract_train3" project root in terminal. Script automates training process steps mentioned above and generates "foo.traineddata" for hieroglyphs. Now we can test tesseract with new data:
tesseract foo.bar.exp0.tif stdout -l foo --psm 6 --tessdata-dir ./tessdata/ ABCDEF
or say another image, not used for training, scaled and from ancient natives:
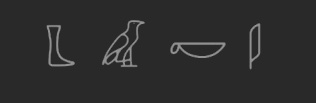
tesseract test1.jpg stdout -l foo --psm 6 --tessdata-dir ./tessdata/ BACE
Note: Direction of writing for ancient Egyptian is multiple - default is right to left, but possible left to right and top to bottom. Usually hieroglyphs face toward to the beginning of reading. Applying to our manuscript it should be OCR-ed as FEDCBA and ECAB. For someone who need in this functionality - unicharset file allow to specify glyph direction.
Note: In clustering step (5) it's possible to execute "shapeclustering" in our case to improve recognition of Indic languages.
Source Code https://github.com/vmdocua/tesseract_train3 on GitHub.